【深度技术】AIAgent上线即翻车?AWS用数据驱动的质检体系破解生产环境验证困局
2025年Q4,我负责的AI客服Agent第三次在生产环境崩溃。Demo演示时领导拍板“就这个了”,结果真实用户一进来,工具调用乱套、回答质量飘忽、各种预想之外的场景轮番爆发。那一刻我意识到:传统软件测试的“确定性验证”逻辑,根本hold不住大模型输出的本质——不确定性。
从“体温计测地震”说起:传统测试方法论的失效
传统软件测试的核心假设是:相同输入必然产生相同输出。单元测试、集成测试、端到端测试,这套方法论运行数十年,成熟可靠。但AIAgent的底层是LLM,而LLM天然具有非确定性——同一个问题问三次,Agent可能选三种不同工具、走出三条推理路径、产出三个不同答案。
这意味着:一次测试的结果只能告诉你“可能发生什么”,而非“通常发生什么”。传统测试只关注最终输出是否正确,就像考试只看总分不看单科——数学挂了都不知道。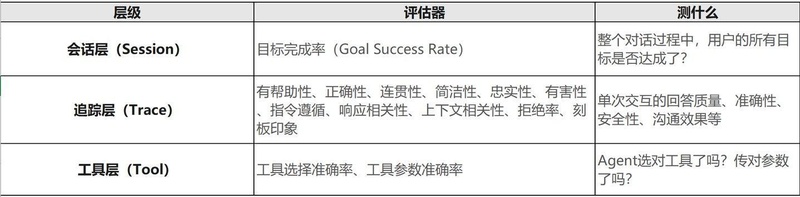
很多团队因此陷入死循环:手动测试→发现问题→修改提示词→再手动测试。API费用烧了一大堆,始终回答不了一个核心问题:“这个Agent现在到底比上次好了没有?”
AgentCoreEvaluations的核心架构:三原则与三层评估
AmazonBedrockAgentCoreEvaluations的设计思路用一句话概括:把“感觉不错”变成“数据说话”。它的技术实现建立在三个基本原则之上:
证据驱动开发——修改提示词后,数据提升了才算数,直觉判断不算数。
多维度评估——独立评估工具选择准确率、参数精度、回答质量等各维度,精确定位问题根源。
持续度量——从开发测试到生产监控,用同一套评估标准贯穿Agent完整生命周期。
技术层面,该服务基于OpenTelemetry(OTEL)标准构建,融入了生成式AI的语义约定(提示词、补全结果、工具调用、模型参数等)。关键特性:框架无关。无论Agent使用StrandsAgents还是LangGraph构建,只要接入OpenTelemetry或OpenInference即可直接使用。
评估体系采用三层结构:
会话层——评估整体交互质量:正确性、简洁性、有帮助性、忠实性、目标完成率。
追踪层——评估Agent推理过程:上下文相关性、推理连贯性。
工具层——评估工具使用精度:工具选择准确率、工具参数准确率。
三层独立评估的价值在于精确定位问题。Agent可能工具选对了、参数传对了,但最终回答质量很差——这种情况只有在各层独立评估后才能发现。
评估器间的依赖与权衡:实战洞察
AWS披露的评估器关系图谱极具实战价值:
依赖关系:“工具参数准确率”仅在“工具选择准确率”高的前提下才有意义——先确保选对工具,再优化参数。“正确性”往往依赖“上下文相关性”——没有正确信息输入,不可能生成正确回答。
矛盾关系:“简洁性”和“有帮助性”经常冲突——过于简洁的回答可能遗漏用户需要的上下文信息。
这一洞察直接指导调优方向:发现“正确性”分数低时,别急着改回答生成逻辑,先查“上下文相关性”是否也不高——问题可能出在信息检索环节。
诊断模式:从“盲人摸象”到“精准定位”
三种典型诊断模式:
模式一:所有评估器分数都很低。通常说明基础性问题。优先检查上下文相关性(Agent是否获取正确信息)、系统提示词(是否有模糊或矛盾指令)、工具描述(是否准确解释工具用途)。
模式二:相似交互分数不一致。大概率是评估器配置问题而非Agent问题。检查自定义评估器指令是否足够具体,降低评估模型温度参数以提高评分稳定性。
模式三:工具选择准确但目标完成率低。说明Agent选对工具但未完成用户目标。可能原因:缺少必要工具,或难以处理多步顺序调用任务。
工程实践:落地策略与效果验证
实战建议从三个维度展开:
选择初始评估器组合时,根据Agent类型优先级差异化。客服型Agent优先关注“帮助性”和“目标完成率”;RAG型Agent重点看“正确性”和“忠实性”;工具密集型Agent盯紧“工具选择准确率”和“参数准确率”。
测试执行层面,每个问题至少测试10遍,按类别分组统计方差,识别Agent在哪些方面稳定、哪些方面需要打磨。
改动验证层面,每次修改前后进行对照实验,让数据说话而非凭感觉判断“好像好了点”。
两种评估模式覆盖Agent生命周期不同阶段:在线评估从生产流量中持续采样,自动评分——传统运维监控(延迟、错误率)可能全是绿的,但用户体验已在悄然恶化,在线质量评分能捕捉这种“无声退化”。按需评估则更像开发实验室,适合验证提示词修改效果、对比模型性能、在CI/CD流水线中执行回归测试。
关键设计:两种模式使用同一套评估器,开发阶段测试标准与生产监控标准完全一致,避免“开发环境正常、上线就崩”的尴尬。



